
Introducing the European Unified RISC-V IP Access Platform (UAP)
This post was originally published in HiPEACINFO magazine, edition #77. Read the print article here.
A first-of-its-kind collection of EU-developed RISC-V components is now available, giving industry and academia access to verified, industry-ready IP from leading European contributors.
By Florian Wohlrab, Head of OpenHW Foundation
Technological sovereignty is a key strategic priority for organisations and governments around the world. Underpinning the digital products that drive modern economies, open source semiconductor IP is increasingly seen as essential to technological sovereignty, enabling stronger collaboration, and more resilient innovation.
The new European Unified RISC-V IP Access Platform (UAP), created by the TRISTAN consortium and hosted by the OpenHW Foundation (an industry collaboration with the Eclipse Foundation) provides a single source of verified, industry-ready RISC-V components under various licenses from TRISTAN, ISOLDE and other European research projects. The UAP designed for engineers, researchers, startups, and established semiconductor teams who need reliable RISC-V IP with clear licensing and maturity information.
While development is ongoing, the UAP already includes multiple software and hardware components that any end user can adopt, marking an important step toward European technology sovereignty:
- Hypervisor support for CVA6 that follows the RISC-V hypervisor extension
- A Yocto-based Linux image for CVA6 processors
- An eXtension InterFace (CV-X-IF) to add custom accelerators into CVE2 RISC-V Cores
- Trace extensions for CVE4
- ELinOS embedded Linux for RISC-V, which includes the CODEO IDE for building industrial-grade embedded solutions
“The Unified RISC-V IP Access Platform is one of the most important initiatives to come from the TRISTAN project, ensuring that the contributions from consortium partners continue to have impact on the European stage long past the end of our funding. Critically, it enables us to build and nurture a community around European RISC-V that will drive ongoing innovation and collaboration that supports European technological sovereignty.”– Rob Wullems, NXP Semiconductors GmbH, TRISTAN Project Lead.
From research to industrial adoption
The European Union sees RISC-V as a strategic lever for technological sovereignty and greater competition in the global semiconductor market, now worth roughly USD 700 billion. While the EU currently represents about 10% of this market, the 2023 European Chips Act aims to double Europe’s share to 20% by 2030.
However, when it comes to semiconductors, achieving technological sovereignty is anything but straightforward. Indeed, the recently published paper, Improving Chip Design Enablement for Universities in Europe, identifies multiple barriers to entry, including costs, legal constraints, and access restrictions. The paper also notes a key gap: too little semiconductor IP is developed and maintained in Europe.
European research projects such as TRISTAN and RIGOLETTO play a vital role in advancing Europe’s semiconductor capabilities. But these are not without challenges. These projects have historically delivered strong technical results, yet many have struggled to achieve market adoption after the project ends. Alongside, short project timelines make it difficult to build communities that can maintain and evolve resulting IP.
The UAP addresses this by giving developers and organisations a single place to find verified, industry-ready RISC-V components developed in Europe
A shared catalogue to keep European IP thriving
The UAP acts as a static unified access page, pointing to repositories hosted on the OpenHW Foundation GitHub, automatically mirrored to a European-hosted GitLab instance and to other public forges, or maintained as private assets. As an evolving structure designed to better support integration across toolchains, accelerators, and infrastructure components, the UAP provides a clear view of each item’s maturity, usability, licensing and integration workflow, including documentation, and status information.
The UAP is overseen by the Virtual Repository Task Group, which includes representatives from TRISTAN and ISOLDE. Other Chips JU and RISC-V-related EU projects such as Rebecca, RIGOLETTO, and Scale4Edge have begun to join. As more EU projects open-source their IP, they will be added as maintainers so that each project can curate its own catalogue and ensure continuity beyond the end of TRISTAN.
More features are planned for the UAP, including KPI-based adoption tracking, extended interoperability matrices, improved tooling, and long-term community development.
“The Unified RISC-V IP Access Platform is absolutely critical to supporting technological sovereignty in Europe, and the OpenHW Foundation and Eclipse Foundation are committed to developing it into a sustainable, interoperable, and community driven resource for the wider RISC-V ecosystem. Open source collaboration is essential to ensuring a competitive playing field, and by working together, we will be able to go further, faster.” – Gaël Blondelle, Chief Membership Officer, Eclipse Foundation
From EU research output to industry adoption
TRISTAN (Together for RISC-V Technology and Applications), which launched in 2023, aims to industrialise RISC-V cores – taking them from the lab to the real world, creating a sustainable open source ecosystem to drive competitiveness and enable more agile innovation on the Continent.
The TRISTAN consortium is a diverse group of 46 partners representing a wide range of stakeholders, from household-name organisations and small and medium-sized enterprises, to research organisations, universities, and industry associations connected to RISC-V. Together, they catalyze expertise and resources from across Europe and beyond to drive innovation and collaboration in the field of RISC-V technology.
The TRISTAN project has resulted in a variety of RISC-V Cores, from deeply embedded and MCU-performance Cores, to verified application-ready Cores. Multiple critical peripheral semiconductor IP has been developed, including Debug, Trace, Interrupt Controllers, Hypervisor support. Alongside, software and simulators have been contributed by a variety of consortium partners.
Live now: how to access and contribute to the UAP
The UAP is now live, featuring both open source and proprietary RISC-V IP from TRISTAN, ISOLDE, Rebecca, and Scale4Edge. If you’re building semiconductor products, we encourage you to explore the catalogue, leverage European RISC-V IP where it fits, and contribute back to strengthen the ecosystem.

Using a Performance Model to Implement a Superscalar CVA6
The OpenHW Foundation's Director of Engineering, Mike Thompson, explains how TRISTAN partner Thales used a performance model to design a superscalar version of the open-source CVA6 RISC-V processor.
By creating a precise cycle-based Python model (99.2% accuracy) to predict architectural improvements, they guided the implementation of a dual-issue CVA6 core.
The result: +40% higher CoreMark/MHz performance with only a small power (+7%) and area (+11%) increase.
Supported by the EU TRISTAN project and the OpenHW Foundation, this work demonstrates how performance modeling can accelerate real hardware innovation in open RISC-V designs.

Support for upstream UVM 2017 in Verilator
This blog was originally published by Antmicro
Universal Verification Methodology (UVM) is one of the most popular verification methods in digital design, focusing on standardization and reusability of verification IP and environments. For the last few years, Antmicro has been gradually completing milestones toward full UVM support in the open source Verilator RTL simulator, from dynamic scheduling (later enhanced with coroutines) through a proof-of-concept UVM testbench running in Verilator to constrained randomization.
With this article, we are happy to announce that Verilator can now elaborate upstream UVM 2017-1.0 - no patches or workarounds required. This important milestone was spearheaded by Antmicro’s efforts within CHIPS Alliance and complemented by the work of Wilson Snyder, the maintainer of Verilator, as well as the broader open source community.
In the following paragraphs, we will summarize Antmicro’s contributions that enabled UVM support in Verilator and describe the most recent developments in the project, including support for features required to enable the examples from the UVM Cookbook. We will also provide a step-by-step tutorial for running Verilator with upstream UVM.

Enhancing Verilator with UVM support and better simulation analysis
Our work with Verilator, be it on new features, bugfixes or enhancements, stems from customer projects, where Antmicro is either providing direct commercial support for Verilator as such for our customer’s ASIC work, or providing digital design and verification services where we use Verilator alongside other tools, both open and closed. On top of the UVM work described in this article, we are thus also making numerous improvements to RTL simulation analysis. From recent examples, to gain more detailed insights into the designs we work with and ensure thorough testing, we have been improving coverage reporting or adding features like support for SAIF to enable more efficient power analysis.
Many of those use cases employ Verilator as a supporting tool, increasing productivity and development speed as well as filling gaps otherwise unserved by other workflows. To push the adoption of Verilator in modern silicon designs beyond its current footprint, especially for verification purposes, solid UVM support is however a must.
Antmicro has been steadily contributing to UVM support in Verilator over the past few years, with the ultimate goal being full UVM support, including complex testbenches. To easily track the progress of these efforts, we leverage our Verilator verification dashboard and SystemVerilog test suite, which together (among other things) help visualize the current state of UVM support in Verilator.
UVM Cookbook support
Antmicro’s most recent contributions have focused on enabling samples from the UVM Cookbook in Verilator, including support for generic interfaces. We also improved the way Verilator handles parameterized classes: we added a step that resolves default class parameters upon instantiation, and fixed other bugs, such as parameter dependent type linking, typedef linking, and passing a type as a parameter. Additionally, we added support for nested classes.
During our work on the examples from the Cookbook, we found a few cases where expression purity was computed incorrectly (a pure expression doesn’t contain side effects). Simple purity measurement was added to Verilator long time ago, and in recent months we significantly expanded it - we fixed purity calculation of dynamic cast operators and the way side effects are handled in select expressions.
Building on top of our previous work on constrained randomization in Verilator, we introduced several new features and fixes:
- Support for
randomize..withwith complex expressions containing accessing object members - Fixing a regression in
randomize..withhandling - Fixing inline constraints with member selects
- Support for
$countonesin constraints - Support for
randomize..withon objects of aliased types - Fixing
randomize..withfor parameterized classes - Partial support for size constraints
- Fixing
randdynamic arrays with null handles - Support for
randdynamic arrays of objects
We also improved the way covergroups are handled by enabling the parsing of covergroup constructs and their initial elaboration. This allows us to exclude them from the code to ensure successful tests when the actual tests function properly but lack covergroups support.
Apart from the UVM Cookbook-related contributions, we also worked on improving the disable statement, namely disabling blocks by label. We had added support for most simple cases a few years back already, and have recently enabled it for cases containing forks, including disabling a fork from within that fork, disabling begin blocks that are directly under fork blocks, and disabling a fork from outside that fork.
Running Verilator with upstream UVM
Previously, Verilator required patches to the UVM source code to elaborate it. Now, thanks to the numerous contributions described in the previous sections, Verilator can elaborate all of UVM 2017-1.0 without any workarounds.
This repository contains an example of how to use UVM with Verilator. Clone it using the following command:
git clone https://github.com/antmicro/verilator-uvm-example
cd verilator-uvm-example
Next, we need to build Verilator. You may need to install some dependencies:
sudo apt update -y
sudo apt install -y bison flex libfl-dev help2man z3
# You may already have these:
sudo apt install -y git autoconf make g++ perl python3
Then, clone and build latest Verilator:
git clone https://github.com/verilator/verilator
pushd verilator
autoconf
./configure
make -j `nproc`
popd
For the full instructions, visit Verilator’s documentation.
Next, download the UVM code:
wget https://www.accellera.org/images/downloads/standards/uvm/Accellera-1800.2-2017-1.0.tar.gz
tar -xvzf Accellera-1800.2-2017-1.0.tar.gz
Now, set up the UVM_HOME environment variable to point to the extracted UVM sources, and PATH to point to Verilator:
UVM_HOME="$(pwd)/1800.2-2017-1.0/src"
PATH="$(pwd)/verilator/bin:$PATH"
To build the simulation, run:
verilator -Wno-fatal --binary -j $(nproc) --top-module tbench_top \
+incdir+$UVM_HOME +define+UVM_NO_DPI +incdir+$(pwd) \
$UVM_HOME/uvm_pkg.sv $(pwd)/sig_pkg.sv $(pwd)/tb.sv
Finally, run the simulation:
./obj_dir/Vtbench_top +UVM_TESTNAME=sig_model_test
Advancing open source RTL verification with Verilator
While support for upstream UVM 2017 in Verilator, partially developed within the European Union’s TRISTAN project, marks an important milestone toward a collaborative, software-driven ASIC development ecosystem, Antmicro continues the work to further enhance the implementation. Our plans for future improvements include adding support for more testbenches and, eventually, UVM 2020, as well as UVM-adjacent verification features.

Extending RISC-V with SCAIE-V: Portable, Efficient, and Scalable Custom Instruction Integration
By Tammo Mürmann, Technical University of Darmstadt
Download the handout here for in-depth information and project links.
Systems that require low power consumption or high performance often employ in-hardware accelerators to meet these demands. While complex algorithms can be efficiently offloaded to memory-mapped accelerators, small computational kernels are typically unsuitable due to overhead and latency. For these cases, custom instructions provide a more efficient acceleration path. However, custom instructions introduce new challenges, including the need for tight integration into the processor pipeline, which can reduce portability.
Although tools for Instruction Set Architecture Extension (ISAX) integration exist, many are commercial, limited to specific core families (e.g., RoCC), support only a subset of instruction types (e.g., no memory access in CV-X-IF), or are still work-in-progress (e.g. RISC-V CX).
SCAIE-V overcomes these limitations by providing a flexible and efficient interface that integrates directly into the processor pipeline. Its logic generation framework supports portability across cores, simultaneous integration of multiple ISAXes, arbitrary instruction encodings, and stateful instruction behavior.
To support a wide range of use cases, SCAIE-V offers three instruction execution modes:
- Tightly-coupled instructions execute in lockstep with the processor pipeline.
- Semi-coupled instructions also execute in lockstep but may span multiple internal stages per pipeline stage, enabling more complex computations.
- Decoupled instructions execute independently and may write back at any time, with hazards automatically managed by SCAIE-V.
In addition, SCAIE-V supports instruction-independent behavior, enabling operations that are decoupled from specific instruction execution, like zero-overhead loops.
SCAIE-V is compatible with several well-known RISC-V cores of varying complexity, such as PicoRV32, VexRiscv, CVA5, and CVA6. Implementation in a modern 22nm ASIC process demonstrates minimal overhead and significant performance gains.

Longnail: Hardware Synthesis of CoreDSL Custom Instructions for MCU- and Application-Class Cores
This blog was originally published by RISC-V International
By Tammo Mürmann, Florian Meisel, and Andreas Koch, Technical University of Darmstadt
Custom Instruction Set Architecture eXtensions (ISAX) are an energy-efficient and cost-effective way to accelerate modern workloads. However, implementing, integrating, and verifying an ISAX into an existing base core is a very time-consuming task that only a few can do. Experimenting with combinations of ISAXes and base cores often requires a complete redesign due to lacking portability across different microarchitectures.
To address these shortcomings, as part of the projects Scale4Edge and FlexKI, we have developed our own end-to-end flow that is the subject of this blog post.
CoreDSL
To make the description of ISAXes accessible to domain experts, we have created the open-source high-level language CoreDSL. Figure 1 shows an example of CoreDSL code to describe an ISAX computing the dot product between two packed vectors. CoreDSL combines familiar C-like syntax and constructs, such as the for-loop in Line 10, with the means to express arbitrary bit-widths (cf. Line 9), while having a strong type system that prevents unintentional loss of precision and sign information. Due to the latter, an explicit cast from the signed<32> to unsigned<32> is required in Line 15 for the assignment to X[rd] to be legal. CoreDSL has been designed from the ground up to concisely express ISAXes, including their encodings and architectural state, without having to deal with low-level details such as clock cycles and resource allocations. Hence, ISAX descriptions written in CoreDSL are naturally vendor-independent and can be used as a single source-of-truth across all steps of the tool flow (e.g., compiler, simulator, etc.).
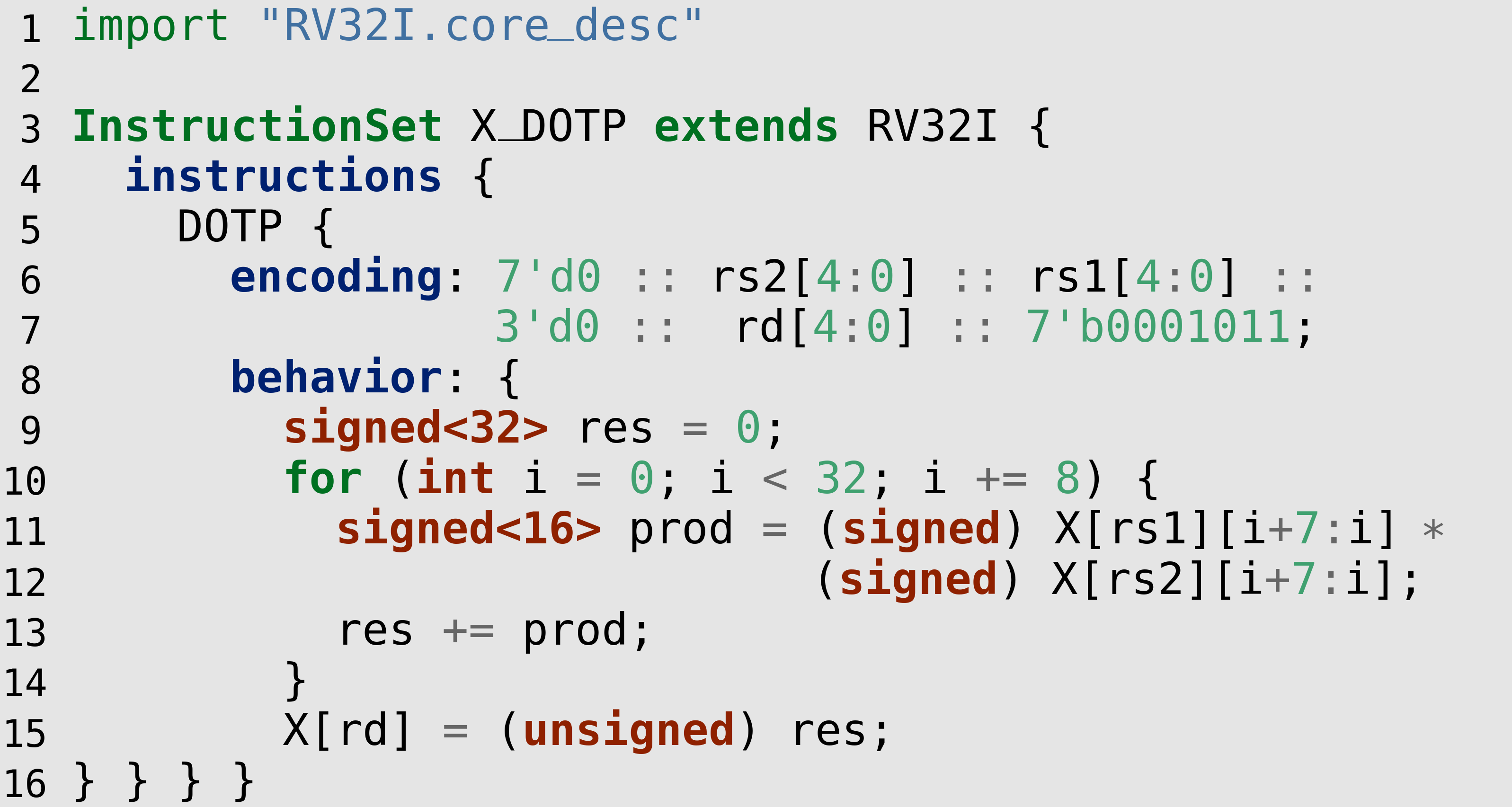
Figure 1: CoreDSL code snippet describing a packed dot product instruction
From CoreDSL to a customized RISC-V core
While CoreDSL is microarchitecture-agnostic, actually implementing and integrating an ISAX is highly dependent on the targeted RISC-V base core. Different microarchitectures influence when operands are available and when results have to be written back.
Our toolflow has two key components: Longnail and SCAIE-V (cf. Figure 1). Longnail is responsible for bridging the gap from the high-level ISAX description, written in CoreDSL, to low-level Verilog code. This step is called high-level synthesis (HLS) and is the key enabler for descriptions that are both concise and portable across different base core microarchitectures. However, just generating the Verilog RTL for the ISAX is only one part of the solution. The ISAX must adhere to some interface to communicate with the base core. For this purpose, our SCAIE-V tooling generates a bespoke core-ISAX interface, custom-tailored for the actual needs of the current ISAX. This not only reduces overheads to the minimum, it also provides Longnail with a “virtual datasheet” of the core, describing, e.g., cycle-constraints on the availability of ISAX operands or results.
SCAIE-V has recently been extended to not just support microcontroller (MCU)-class base cores, but also the far more complex Application-class cores CVA5, in the MANNHEIM-FlexKI project, and CVA6, in the TRISTAN project.
In a nutshell, SCAIE-V supports ISAX-internal state, custom memory accesses and control-flow, and four different execution modes for the ISAX:
- In-pipeline: Longnail ensures that the ISAX matches the base core’s pipeline, and infers stall logic to allow for longer multi-cycle ISAXes.
- Semi-coupled: For long-running ISAXes, SCAIE-V transparently generates stalling logic for MCU-class cores. However, for Application-class cores, SCAIE-V is able to reuse the core’s existing hazard handling logic to prevent stalling.
- Decoupled: As an alternative to the semi-coupled mode, decoupled ISAXes are retired from the processor pipeline before completion, freeing up processor resources. For late register writebacks, SCAIE-V then instantiates its own data hazard handling logic.
- Always: For background tasks that continuously observe and optionally manipulate the pipeline (e.g., hardware loops). Longnail’s always blocks execute independently from fetched instructions, and communicate with software using custom registers provided by dedicated ISAX, which, e.g., set the loop limits for a hardware loop.
For a detailed description of the individual tools, please refer to our publications: SCAIE-V DAC22 paper and Longnail ASPLOS24 paper, respectively.
In addition, SCAIE-V has been released as open-source. It is also proven -in-silicon, having successfully been taped-out as part of a 22nm system-on-chip (cf. SCAIE-V DATE24).
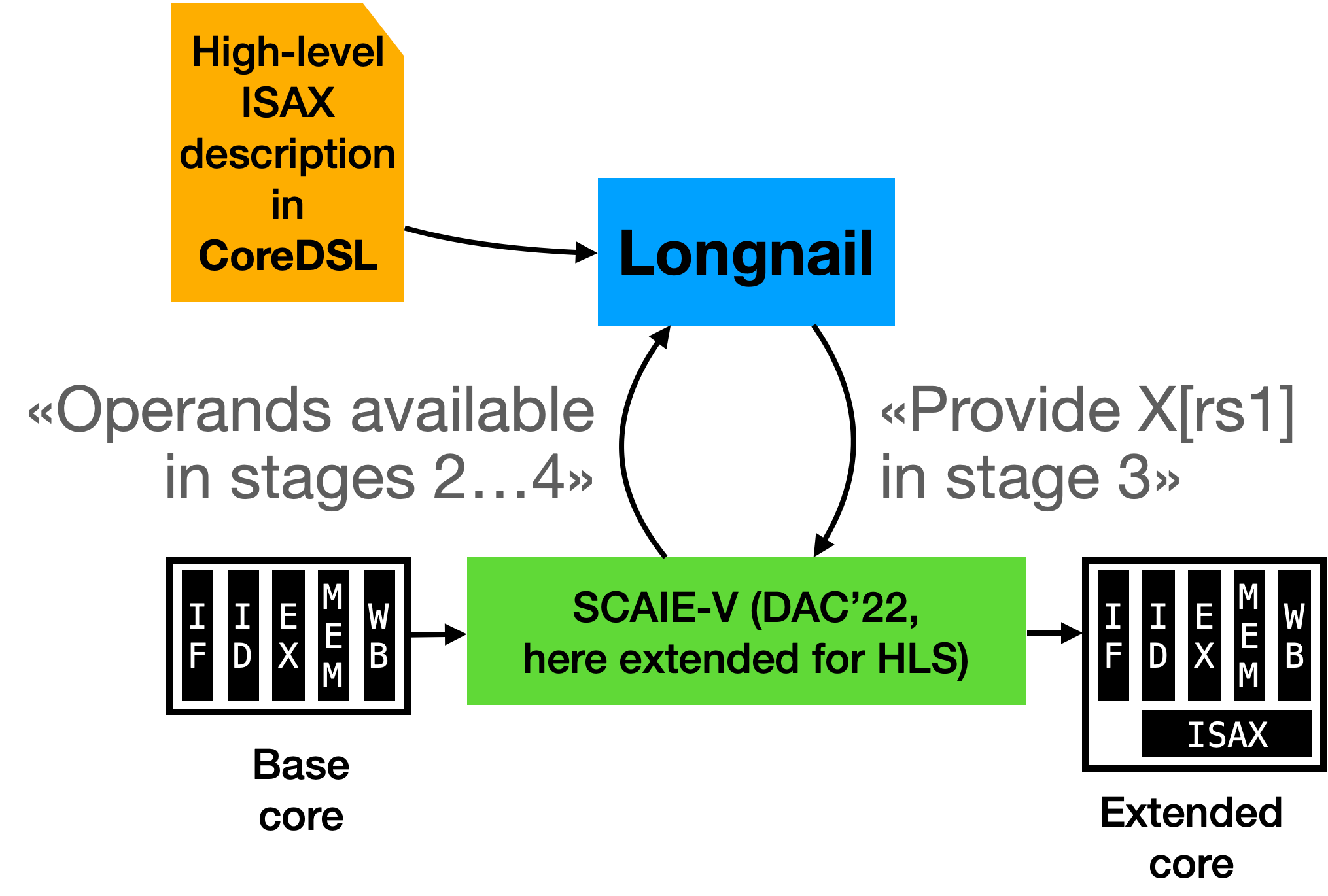
Figure 2: End-to-end flow
For a proper end-to-end flow, we have added automation to invoke our tools with minimal required user interactions. This has been demonstrated at the RISC-V Summit Europe 2024.
Note that our toolflow not just covers the hardware/HLS angle, we also automatically create a customized LLVM-based compiler for using the ISAXes as instrinsics.
On the verification side, we allow the co-execution of C++ based software code using the intrinsics together with an RTL simulation of the ISAXes, without the need to fully simulate the entire base core.
Evaluation
Since our ASPLOS paper, we have added support for CVA5 and CVA6 as Application-class base cores to SCAIE-V, as well as new resource-sharing capabilities to Longnail to reduce the hardware footprint of the interface. We present results obtained on a 22nm ASIC process, using commercial EDA tools for implementation.
ASIC results
While a simple arithmetic instruction (e.g., sbox) will have a low impact across the board, more complex instructions (e.g., dotprod, sparkle) naturally require more hardware area.
Furthermore, the base core microarchitecture matters: For ORCA, the frequency impact of the semi-coupled sqrt instruction is 32%, while the pipeline-decoupled variant slows the core by just 5%, and has a lower area overhead as well. Note that the ISAX hardware and the base core are unchanged, only the integration into the core is different.
The zol hardware loop in general also has a low frequency cost, although it does reduce the timing slack in the core’s “next PC” logic, which reflects on the area utilization of VexRiscv in particular.
On the other hand, the larger CVA5 and CVA6 Application-class cores only see single-digit percentage area and frequency overheads across our entire benchmark set. Being designed to work well with multiple execution units right from the start, these cores see only a minor frequency cost, even for the more complex ISAXes.
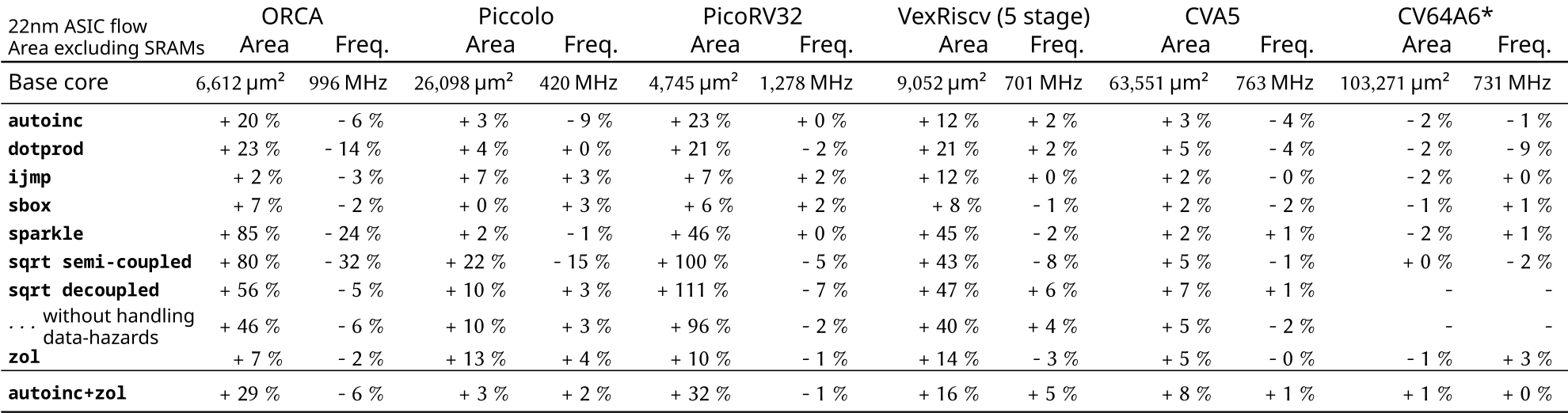
Figure 3: Area and frequency results for a variety of base cores and ISAXes
* preliminary results (CVA6 support is work-in-progress)
Resource Sharing
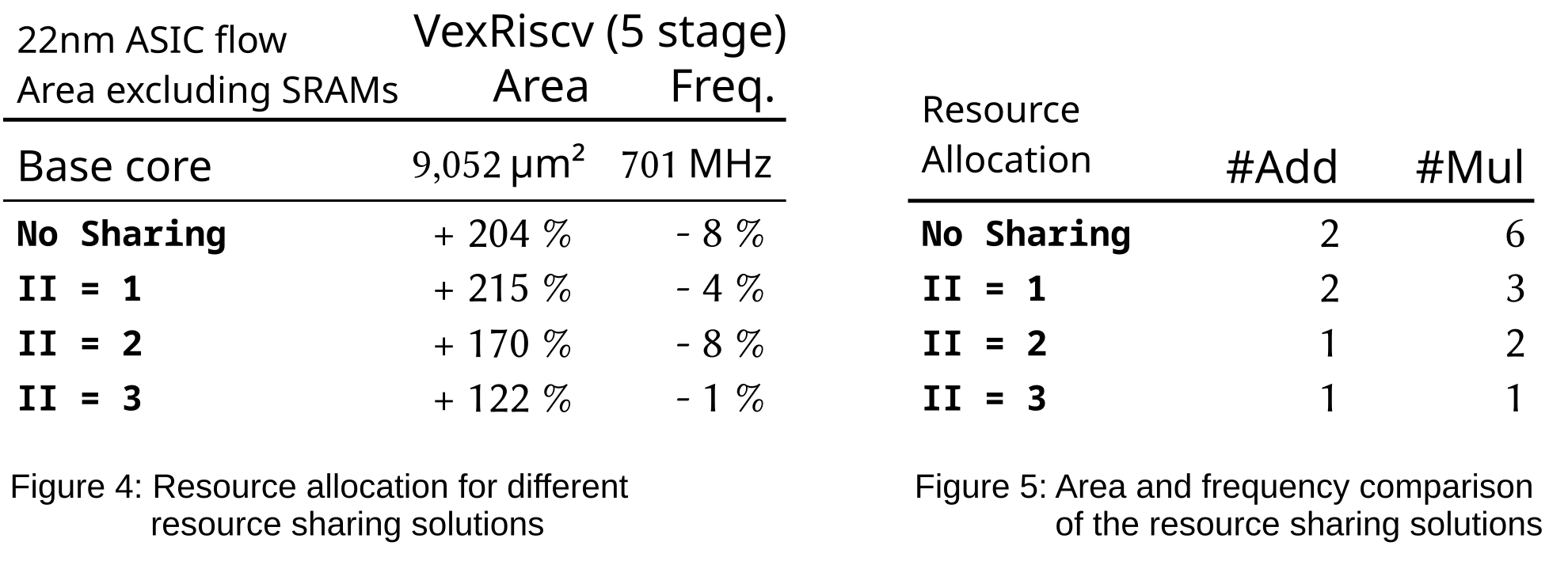
To evaluate the new resource sharing in Longnail, we used a custom vector ISAX. Our vector extension uses its own register file with four three-dimensional vectors and contains instructions for a dot product and an element-wise multiply. Hence, as shown in Figure 4, up to six multipliers and two adders would be required for a fully spatial implementation.
However, Longnail can exploit the microarchitectural details of the base core (here: VexRiscv), as provided by SCAIE-V in a “virtual datasheet”, to perform resource sharing halving the number of multipliers, and still allow executing a vector ISAX each cycle (II=1). Further savings are possible when a reduced issue rate for the ISAX is acceptable, e.g., just every second or third clock cycle (II=2 and 3).
Sample resource-sharing results are shown in Figure 5. Frequency changes remain within the range of EDA tool heuristics noise. Similarly, area savings become notable only at II=2 and 3.
Acknowledgments
Supported by the German Federal Ministry of Education and Research in the projects “Scale4Edge” (grants: 16ME0122K-140, 16ME0465, 16ME0900, 16ME0901) and “MANNHEIM-FlexKI” (grant: 01IS22086A-L). This work has received funding from the Chips Joint Undertaking (CHIPS-JU) TRISTAN project under grant agreement No 101095947. CHIPS JU receives support from the European Union’s Horizon Europe research and innovation programme.
Conclusion
We presented our end-to-end flow from an ISAX formulated in CoreDSL, to synthesis-ready RTL generated by Longnail HLS, and finally to its integration into a base processor using the SCAIE-V tooling. Our flow abstracts the microarchitecture of the target core, reducing the barrier-to-entry for domain-specific additions to the ISA, while also allowing portability across multiple cores supporting advanced ISAX features.
Our findings show that our approach is effective for both MCU- and Application-class cores. Additionally, Longnail’s new configurable resource sharing helps to further optimize the extension’s implementation, matching it to the concrete needs of the application.

From guesswork to guidance: Mastering processor co-design with Codasip Exploration Framework
This blog was originally published by TRISTAN partner Codasip.
By Alexander Schober, Innovation Team Leader
For decades, the art of designing complex System-on-Chips (SoCs) has been a delicate balancing act. The intricate dance between hardware and software, known as co-design, has been guided primarily by the seasoned experience of architects. They navigate a vast, multidimensional space of possibilities, where every tweak to a hardware configuration or a line of software code can send ripples across the holy trinity of chip metrics: power, performance, and area (PPA).
This reliance on intuition, however, is reaching its breaking point. As configurable IP cores -particularly those based on the open RISC-V standard – unlock an explosion of design possibilities, the traditional approach is no longer sustainable. The sheer scale of this new design paradigm necessitates a fundamental shift.
Highly configurable processor IPs offer a powerful advantage: the ability to match hardware resources precisely to the needs of the software. This means software can run more efficiently, while silicon area is used more economically. But with this flexibility comes complexity. And that’s where Codasip steps in.
Custom compute, made practical
As the European leader in configurable processor IP, Codasip is uniquely positioned to address this challenge. Our mission is to empower innovators to architect their ambition—by giving them the tools to design processors that are not just different, but better.
At the heart of our offering is Codasip Studio, our automated processor design toolset. It uses CodAL, a C-like architectural language, to describe both the instruction set architecture (ISA) and the microarchitecture of a processor. From a single CodAL description, Codasip Studio generates both the hardware development kit (HDK) and software development kit (SDK), ensuring consistency across the entire design flow.
This foundation enables us to offer processor IPs with an exceptional degree of configurability. Our cores are designed with a wide range of features that can be turned on or off, or tuned to specific values. This means a single Codasip processor family can replace multiple off-the-shelf cores, offering a tailored fit for each application workload. Just look at the example below. By adding more configurable features, the performance of our configurable cores can significantly grow. However, adding features also increase the silicon idea. This is why finding the right configuration for your software workload is critical.

While this flexibility is a major advantage, it also introduces a new challenge: how do you efficiently explore such a vast configuration space?
The complexity of choice
When working with configurable IP, the number of possible configurations can be overwhelming. Each option – whether it’s enabling a feature, adjusting a parameter, or selecting a compiler flag – can influence the final PPA outcome. And when you factor in the impact of different compilation strategies on software performance, the space of potential combinations grows even larger.
Manually evaluating all these configurations is not just time-consuming – it’s impractical. Most teams end up preselecting a few configurations to test, which risks missing the optimal one. Even when multiple configurations are tested, ensuring that the results are comparable and meaningful requires a systematic and rigorous approach.
This is where Codasip’s new solution comes in.
Introducing the Exploration Framework
To help our customers fully exploit the configurability of our processor IPs, we’ve developed a new tool: the Codasip Exploration Framework.
This framework automates the process of evaluating numerous processor configurations directly against real-world user applications, not just synthetic benchmarks. It enables users to:
- Define which cores and configurations to include in an automated test run
- Automatically generate the necessary SDKs, simulation models and RTL using Codasip Studio
- Specify multiple compiler toolchains, compilation scenarios and different compiler flags
- Run user provided software workload or benchmark on each configuration using either simulation models or RTL simulation
- Collect and report key metrics for each run, including:
- Number of cycles to execute the application
- Code size of the compiled application

By automating this process, the Exploration Framework makes it easy to compare how different processor configurations perform under various compilation strategies. This helps users identify the most suitable configuration for their specific workload – without the guesswork.
Designed for flexibility
The Exploration Framework is goal-driven by design, offering both flexibility and a user-friendly interface. Customers can either run the standard benchmarks or more importantly provide their own software applications. Users have the flexibility to deploy the tooling wherever it’s needed. It can be run on a local machine, a private distributed system, or in the cloud for ultimate scalability. The tool handles the heavy lifting, allowing engineers to focus on interpreting results and making informed design decisions.

A spark of innovation: The TRISTAN connection
This shift from intuition-based design to a data-driven approach was not born in a vacuum – it was forged through the power of collaborative research and development. Collaborative innovation is at the heart of our mission, and our involvement in the TRISTAN project is a prime example. Working alongside industry-leading European organizations, we tackled the complex challenge of evaluating performance for various hardware IPs. This collaboration provided a unique opportunity to gather requirements and use cases directly from our partners, which in turn sparked the idea for a product-grade solution. This effort ultimately led to the development of the Exploration Framework, a powerful demonstration of how research and development consortia projects bring together diverse partners to drive meaningful innovation and transition research into real-world applications.
Architect your ambition
At Codasip, we believe that the future of processor design lies in customization. But customization must be accessible. The Exploration Framework is our latest step in making that vision a reality – helping customers unlock the full potential of RISC-V and build processors that are truly optimized for their applications.
Whether you’re designing for automotive, industrial, or edge AI, Codasip gives you the tools to take control of your design destiny. With the Exploration Framework, you can move from guesswork to guidance – and architect your ambition with confidence.
The “TRISTAN” project has received funding from the European Union HE Research and Innovation programme under grant agreement No 101095947. Codasip Gmbh, as a German participant in this project, is supported by the Federal Ministry of Education and Research under grant no. 16MEE0275.
Views and opinions expressed are however those of the author only and do not necessarily reflect those of the European Union, Federal Ministry of Research, Technology and Spacein Germanz and KDT JU. Neither the European Union nor the granting authority can be held responsible for them.

Enhancing RTL coverage reporting in Verilator with new features and computation optimizations
This blog was originally published by Antmicro
Monitoring code coverage in digital design projects requires tracking both traditional software metrics such as executed code lines and visited branches, as well as more use-case specific concepts such as bit field toggles of signals. Analyzing coverage information generated by HDL simulators can be done using Antmicro’s Coverview tool, and detailed, interactive visualization of the results of your tests helps ensure your design is thoroughly tested.
In our digital design projects, we often use (and improve) the open source Verilator RTL simulator, which includes support for different types of coverage required by RTL projects, and given its open source nature, we can improve and adapt it to the needs of our projects and tightly integrate it into our (and our customers’) workflows.
In this article we will summarize the current state of code coverage support in Verilator and describe the features and improvements that we recently introduced to improve Verilator’s usefulness for this use case.

Coverage reporting in Verilator
Verilator handles coverage measurement by automatically inserting counters to SystemVerilog code, which are incremented each time a statement is executed or a bit changes its value. In most cases, users don’t need the exact values of counters, only the information whether they are 0 or not. If a counter is non-zero, it means that a statement/bit was covered by at least one of the tests at least once.
In the end, Verilator generates .info files that can be then used with Antmicro’s Coverview tool to generate interactive coverage dashboards, as described in more detail in a recent article.

There are four types of coverage that are currently supported in Verilator: branch, line, expression and toggle coverage.
Branch coverage shows how many times each of the branches was executed. For example, an if statement contains two branches: if (condition) { 1st branch } else { 2nd branch }. To measure this type of coverage, Verilator creates a counter for each branch and places its incrementation in that branch. This incrementation is executed the same way as any other statement.
Line coverage demonstrates how many times the code from each line was executed during the tests. Similarly to branch coverage, it is handled by counter insertion. With the exception of constructs that introduce branches, statements are executed one by one. Keeping a separate counter for each line would significantly reduce the performance of simulation, so instead, the counter information is stored for a given range (or ranges) of lines and only one incrementation is inserted. In the example below there is one counter for two ranges. The first range is from while to if (x == 10) , and the second from z++ to x = y + z;. The body of if isn’t evaluated in every iteration of while, so it has to have a separate counter. Statements after the if body are evaluated the same number of times as statements before if, so they have the same counter.
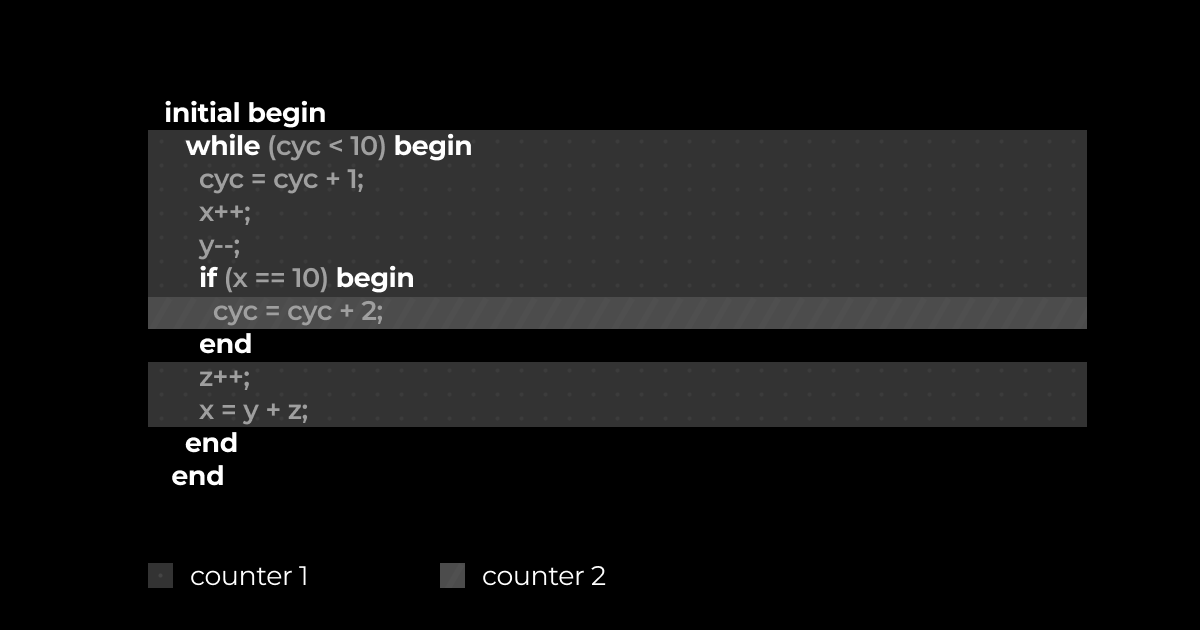
Expression coverage shows how many times sets of subexpressions of a Boolean expression cause its evaluation to a given value (true or false). It is handled by inserting if statements containing counters. Conditions of these if statements are conjunctions of subexpressions to which the counter relates. Each of these subexpression sets has its own counter.
Toggle coverage illustrates how many times each bit of each variable changed its value. Computing this type of coverage is more complicated than other types, as the counter is not incremented directly after the change of value. Previously, Verilator only had a single counter for changes both from 0 to 1 and from 1 to 0. As described in the section below, Antmicro recently introduced separate counters for each type of value change.
New features and improved coverage computation
While using Verilator to analyze code coverage for the digital design projects we are working on, we identified several ways to optimize the coverage computation process, but also found and fixed a number of bugs, some of them not strictly related to coverage. Coverage measurement in Verilator involves using constructs that are also used in other contexts, but some of them rarely. After we started using them more often for coverage computation, we could easier find bugs related to those constructs and later fix them, which led to improvements in Verilator beyond just coverage reporting. For example, coverage measurement utilizes an internal Verilator construct, which allows executing a list of statements within an expression. It is an equivalent to C++’s immediately invoked lambda function. In some cases, such an expression was cloned multiple times, which resulted in multiplication of side effects. We found and fixed an example in which the number of duplicated side effects grew exponentially.
In order to produce .info files, the raw Verilator coverage output (generated during simulations of the model created by Verilator) has to be processed with the verilator_coverage tool. Previously, if a user wanted to generate reports for both toggle and branch coverage, they had to run the whole process twice (i.e. verilation, compilation, simulation, processing with verilator_coverage). We added an option to select the coverage type in verilator_coverage, which means now only processing with verilator_coverage needs to be repeated, and since it’s the fastest step of that process, this change saves a lot of time.
We also introduced several improvements for specific coverage types, including adding ternary operators to branch coverage and variables defined in generate blocks to toggle coverage. Additionally, we separated toggle coverage counters for changes from 0 to 1 and from 1 to 0.
Some of Antmicro’s other recent contributions to Verilator related to coverage include:
- optimizing the way toggle coverage is computed,
- cleanup of the coverage-related code,
- fixing coverage of complex type variables.
Those improvements, as used in several projects we’re involved with including e.g. Caliptra, have allowed us to introduce more detailed and easily reproducible coverage reporting and measurement, making it easier to iterate and communicate around verification coverage in collaborative projects.
Open source RTL verification with Verilator
The implementation introduced in this note was partially developed within the EU-funded TRISTAN project aiming at creating and improving more open and reusable tooling for RISC-V SoC development. Verilator’s coverage reporting features, combined with its integration with tools such as cocotb and Renode, provide verification engineers with actionable insights into their designs. Antmicro offers engineering support in customizing and optimizing Verilator, even for large and complex designs. If you’re interested in integrating Verilator with your existing workflows or would like to learn more about Antmicro’s related tools for coverage analysis and test planning, reach out to us at contact@antmicro.com

Strengthening European Sovereignty through Open HW: Insights from the RISC-V Summit Europe
At the recent RISC-V Summit Europe in Paris, Florian Wohlrab took the stage to present how the TRISTAN and ISOLDE projects are actively contributing to the growing RISC-V ecosystem, particularly through their alignment with the RISV-C initiative.
The presentation highlighted how these collaborative European efforts are not only pushing the boundaries of open hardware but also enabling SMEs across the continent to develop sovereign, high-performance computing solutions using RISC-V technology. By fostering innovation through projects like TRISTAN and ISOLDE, the European Union is laying the groundwork for a robust, self-reliant digital infrastructure.
Several companies involved in these projects were showcased, each demonstrating their unique contributions to the shared vision of open, secure, and competitive computing platforms. This reflects a broader commitment within the EU to support technological independence while still embracing global standards and communities like RISC-V International.
To learn more about the RISC-V initiative and the role Europe is playing in shaping its future, visit RISC-V International.










Join Us for the EDGE AI Academy Summer School in Pisa – July 7–8, 2025!
We’re thrilled to announce the EDGE AI Academy Summer School 2025, taking place July 7–8 in the beautiful city of Pisa, Italy!
This dynamic two-day event is a unique opportunity for students, researchers, and professionals to enhance their skills, gain hands-on experience, and connect with fellow learners and experts in the rapidly evolving field of Edge AI.
-
Location: Pisa, Italy
-
Dates: July 7–8, 2025
-
Watch the Teaser Video:
https://youtu.be/vNsD0HFWitw?si=JJCRH7xmF4oPeewM
What to Expect
The EDGE AI Academy Summer School is designed to empower participants with:
- Advanced knowledge of Edge AI and IoT
- Insight into the RISC-V architecture and ultra-low-power computing
- Practical, hands-on learning experiences
- Real-world applications and use cases
- Team-based projects to promote collaboration and innovation
You’ll learn how Edge AI is revolutionising computing by processing data closer to its source—enabling faster decision-making, improved privacy, and reduced reliance on cloud infrastructure.
This is your chance to explore the forefront of intelligent systems and join interactive lectures, workshops, and networking activities led by top experts in the field.
Who Should Apply?
We welcome:
- Master’s graduates
- PhD students
- Young researchers
- Industry professionals
If you’re passionate about the future of AI, IoT, and embedded systems, this summer school is for you.
How to Register
-
Application Form for Academic Partner Candidates: Apply Now
-
General Registration Link: Register Here
⚠️ Please note: Space is limited! Be sure to register early to secure your spot.
For any questions or additional information, don’t hesitate to reach out. We look forward to welcoming you to Pisa for an inspiring and enriching summer experience!
Warm regards,
The EDGE AI Academy Summer School Organising Committee

Enabling complex HDL co-simulation scenarios using Renode's Direct Programming Interface support
This blog was originally published by Antmicro
When developing complex FPGA designs and custom SoCs, simulating and testing HDL designs in a larger context is necessary to accurately replicate real use cases. For fast iteration, you can combine cycle-accurate RTL simulation of elements of your design undergoing most heavy modifications with functional simulation using Antmicro’s Renode framework for “best of both worlds” in terms of performance vs. accuracy.
Renode’s HDL co-simulation ecosystem includes support for SystemVerilog DPI (Direct Programming Interface), which provides integration with a wide range of popular tools such as Verilator, Questa and VCS. In this article we summarize DPI support in Renode and describe new co-simulation features in two setups: with a virtualized interconnect and with an HDL interconnect. These new capabilities were developed partly within the European Union’s TRISTAN project, which focuses on providing open IP and development ecosystem for RISC-V projects.

DPI support in Renode
Co-simulation is especially useful in pre-silicon development projects or in FPGA SoC-based product development, bridging the gap between software and digital design engineers, allowing them to work in a single environment and co-develop hardware and software features of a product. A standardized interface like DPI can cater for both use cases and work across the multiple simulator ecosystems, both open and proprietary.
It’s only natural that the support for DPI in Renode was developed in collaboration with Microchip in the context of their RISC-V based PolarFire SoC FPGA, whose roll-out was supported by Renode even before silicon was generally available.
Currently Renode supports the following bus implementations via the DPI interface:
- AXI4
- AXI4Lite
- APB3
- AHB
To showcase different DPI-based co-simulation scenarios in Renode, we have a renode-dpi-examples repository containing a CI configured to build and run the samples in Verilator.
Historically, Renode supported scenarios with a single range of the memory map (e.g. a single peripheral) forwarded to a single instance of a co-simulation tool, and while it was possible to have multiple peripheral instances, creating blocks that are separate on a bus but connected to a single co-simulation tool instance was harder and less scalable than we’d like. With our recent efforts around co-simulation in Renode focused on extending the DPI support to enable more complex co-simulation scenarios, we provide new abstractions to simplify this process, in two flavors: including an interconnect or with a virtualized interconnect.
Virtualized interconnect
In a virtualized interconnect setup, RTL peripheral modules are connected directly to the Renode DPI integration layer through bus protocol adapters. Transactions are passed directly to Renode, using absolute addresses as defined in Renode platform description. Effectively, the job of directing a transaction to/from a particular peripheral, which is normally performed by an interconnect inside the RTL simulation, is outsourced to Renode.
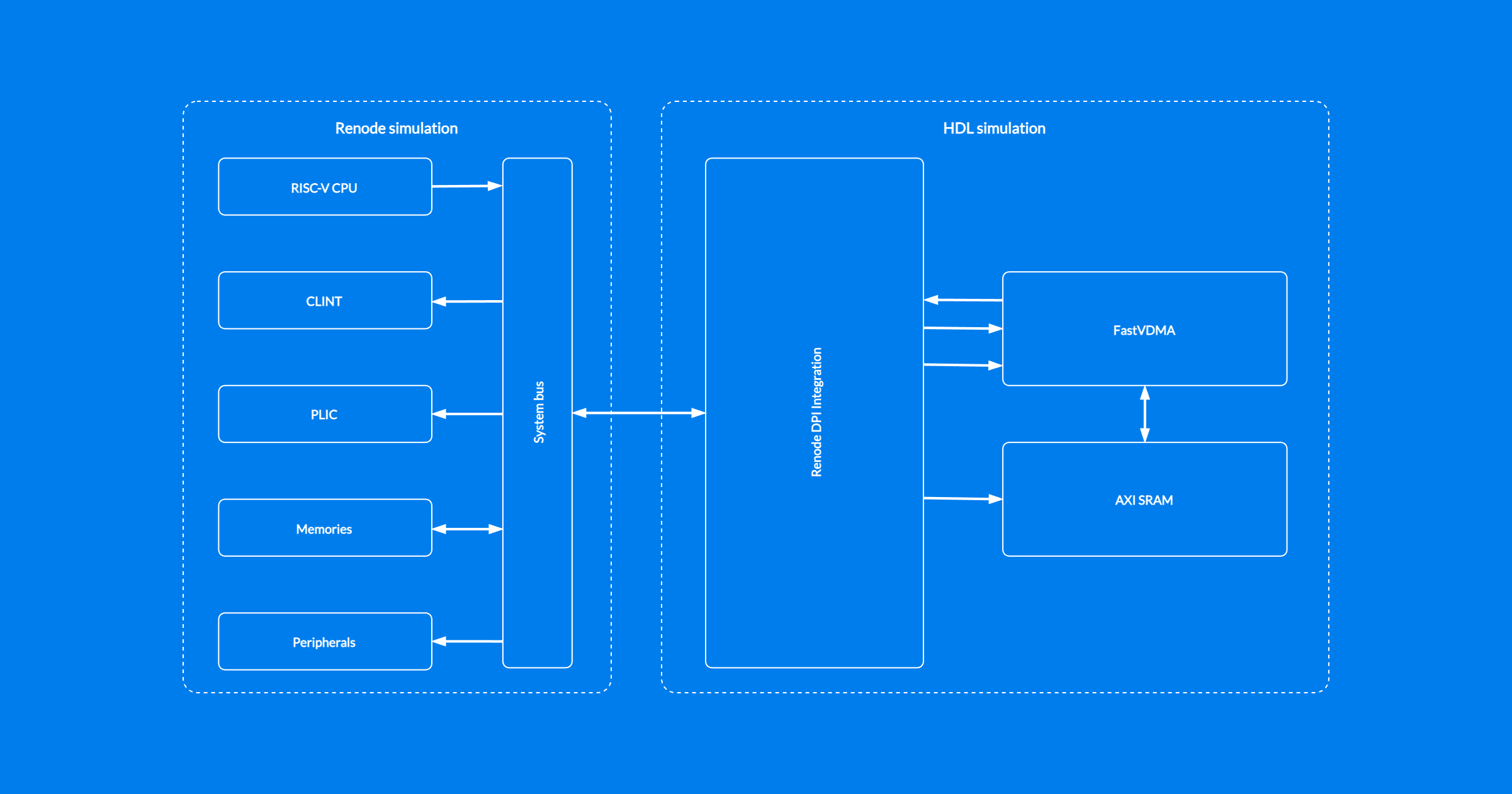
While this approach represents a simplification of the actual system, it provides several benefits: compared to a setup with the interconnect as part of HDL simulation, it is conceptually simpler, doesn’t require you to provide the interconnect IP and is less compute-intensive.
You can find an example scenario with two AXI managers and two AHB subordinates connected directly to Renode using a virtualized interconnect in the renode-dpi-examples repository.
Interconnect as part of HDL simulation
An alternative approach relies on using actual interconnect RTL which has to be provided by the user. Although this setup is more complex compared to a virtualized interconnect, it offers better accuracy of the simulation and the possibility to include various interconnect features, such as request arbitration and prioritization.
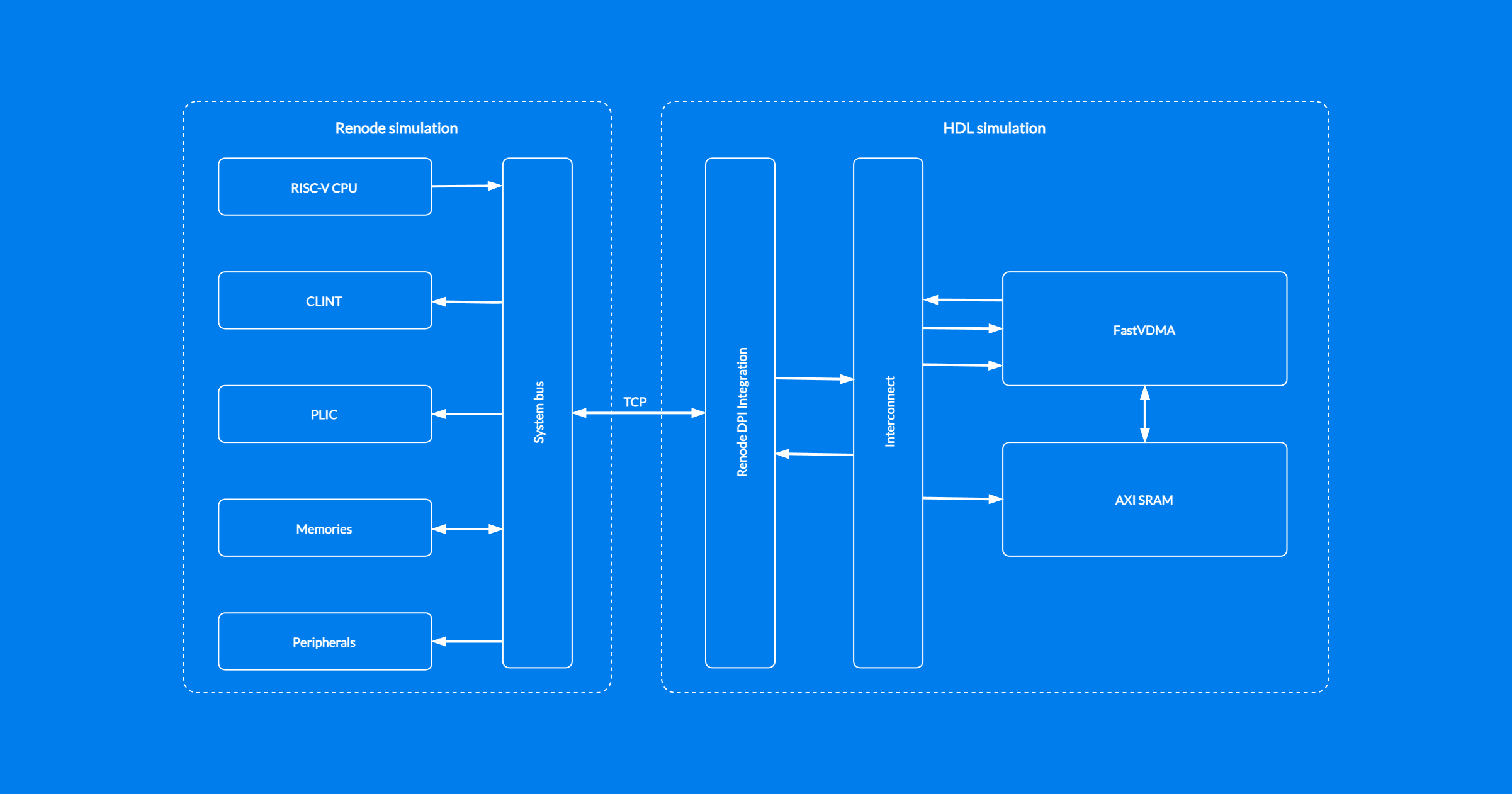
To use the interconnect RTL, you need to include its implementation and correctly configure it to ensure proper routing between connected blocks.
An example scenario based on AXI interconnect RTL is also available in the renode-dpi-examples repository.
DPI-based HDL co-simulation in Renode for accelerated FPGA and ASIC design
Renode’s co-simulation support, which also includes integration with SystemC, can help you accelerate complex hardware-software co-development and testing in a flexible, deterministic environment.
Whether your use case involves pre-silicon development for complex ASICs involving internal management SoCs, or co-developing FPGA SoC IP and drivers, you can most likely benefit from Renode’s comprehensive simulation features.